环境采用qemu-system+gdb,x86_64架构
通过qemu提供的-s接口调试linux kernel
通过gdb attach qemu进程实现访问物理内存
首先还是官方文档里的linux kernel memory map(https://elixir.bootlin.com/linux/latest/source/Documentation/arch/x86/x86_64/mm.rst)
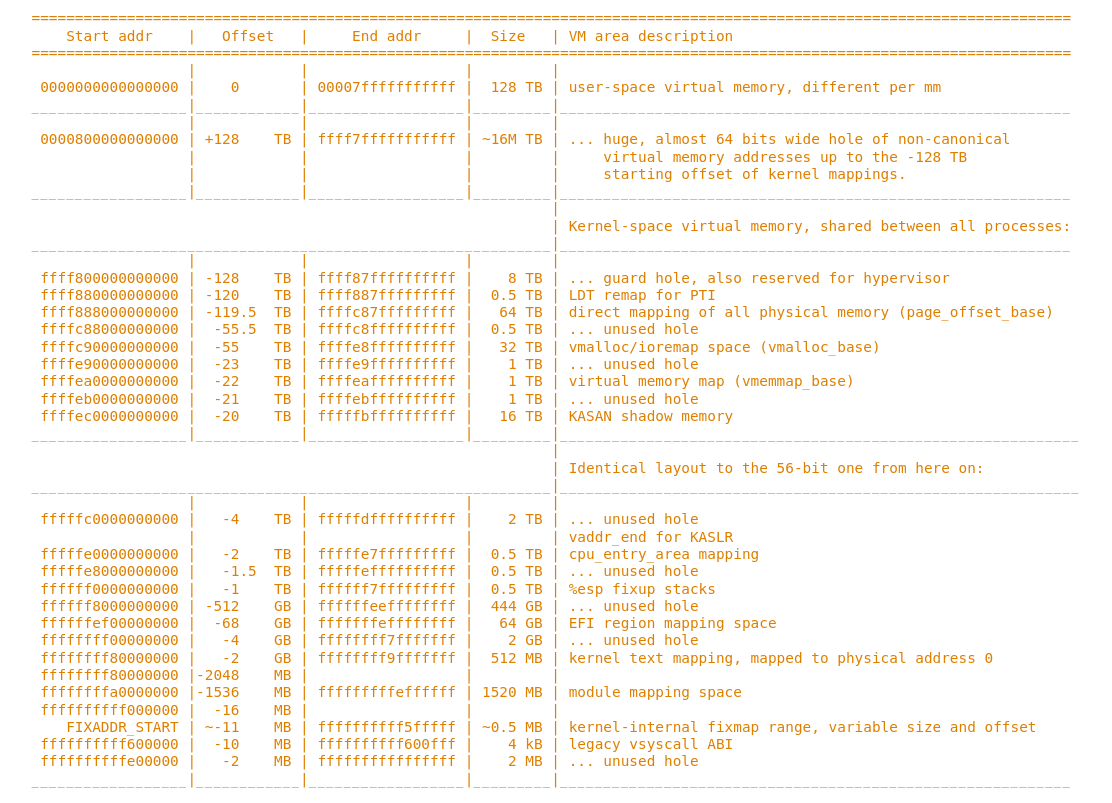
direct map
0xffff888000000000-ffffc87fffffffff
这段长达64T的虚拟内存空间直接映射的所有对应的内存,也就是说从page_offset_base到page_offset_base +
MAX_MEMORY_SIZE的的内存直接对应了整个物理地址空间,这也就意味着除了直接direct map区以外的所有虚拟内存空间在direct map区内都必然存在一个对应的内存页,也就是其他虚拟内存对应的物理地址在direct map区的映射,两块虚拟内存页对应同一块物理内存页
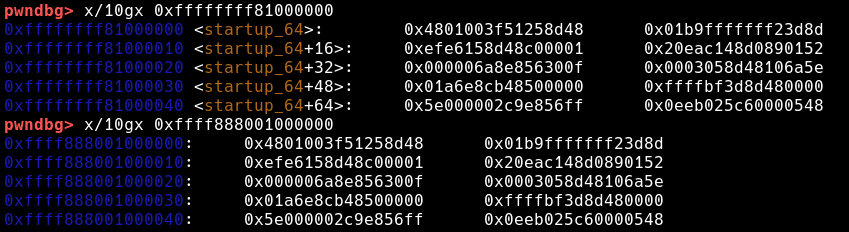
位于0xffffffff81000000地址的linux kernel text在0xffff888001000000地址处存在一个内容完全相同的内存页,并且对于其中任意一个内存页作修改会导致这两个内存页同时被修改,这也同样表示0xffffffff81000000地址对应的物理地址就是0x1000000
对于其他的内存区域也是同理,位于0xffffffffc0000000地址的某个kernel module text同样被0xffff88800267c000映射,二者同样对应同一个物理内存页
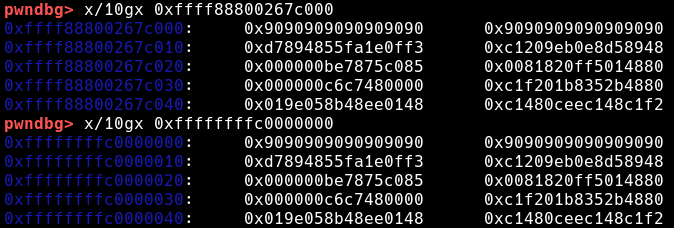
但是要特别注意,两块对应同一个物理内存页的虚拟内存页,其权限并不一定相同,举例来说,r_x权限的linux kernel text段,其在direct map区对应的内存页却是r__的,也就是说,不幸的是,即使获得了任意地址写的能力,也不能通过修改某个?_?的victim page所对应的在direct map区的内存页来实现,因为通常这块内存页的读写权限只会更低,比如r__,当然,通过USMA等方法新映射的内存页不受限制,两块内存页都可以直接被packet_mmap映射成rw_的
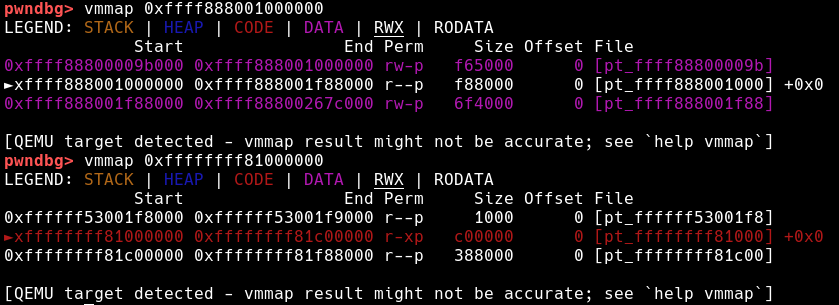
vmalloc space & virtual memory map
之所以把这两快内存区域合在一起提出,是因为这两块内存区域所对应的物理内存的计算方法相同,都需要通过页表查找来实现,而不像direct map一样仅需要减去page_offset_base的固定偏移,
aaaa